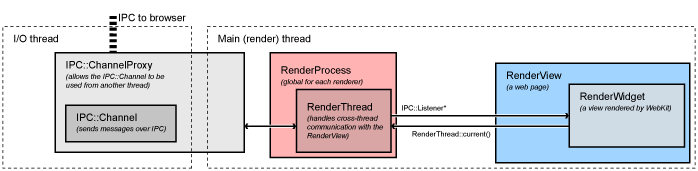
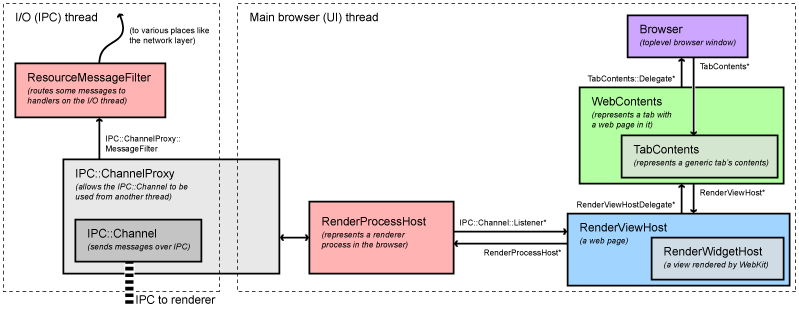
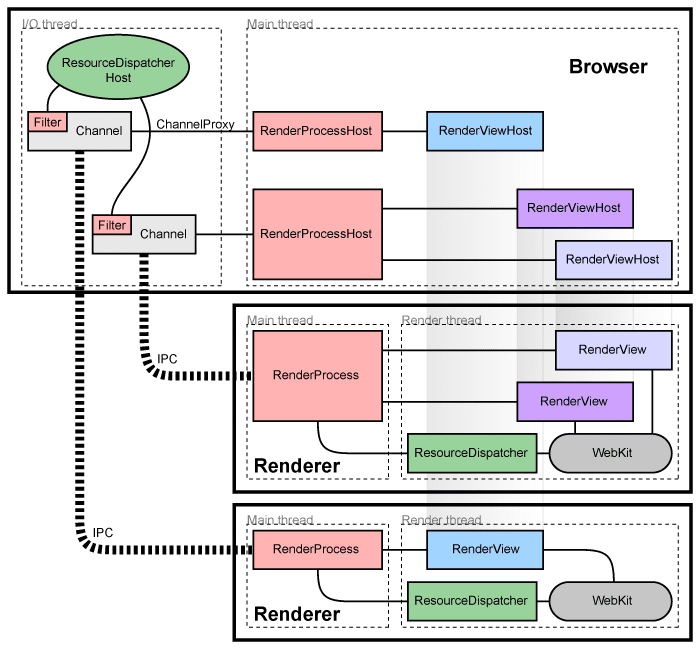
和界面相关的消息大部分在RenderViewHost::OnMessageReceived被处理,剩下的发送给RenderWidgetHost基类,对应于render进程内的RenderView and the RenderWidget
各平台都有自己的显示实现(RenderWidgetHostView[Aura|Gtk|Mac|Win])
#include <iostream>usingnamespacestd;classCComplexObject// a demo class{public:voidclone(){cout<<"in clone"<<endl;}};// Solving the problem of choosing method to call by inner traits classtemplate<typenameT,boolisClonable>classXContainer{public:enum{Clonable=isClonable};voidclone(T*pObj){Traits<isClonable>().clone(pObj);}template<boolflag>classTraits{};template<>classTraits<true>{public:voidclone(T*pObj){cout<<"before cloning Clonable type"<<endl;pObj->clone();cout<<"after cloning Clonable type"<<endl;}};template<>classTraits<false>{public:voidclone(T*pObj){cout<<"cloning non Clonable type"<<endl;}};};voidmain(){int*p1=0;CComplexObject*p2=0;XContainer<int,false>n1;XContainer<CComplexObject,true>n2;n1.clone(p1);n2.clone(p2);}
输出:
doing something non Clonable
before doing something Clonable
in clone
after doing something Clonable
#ifndef MY_DESTRUCT_H#define MY_DESTRUCT_H#include <iostream>#include "my_type_traits.h"usingstd::cout;usingstd::endl;template<classT1,classT2>inlinevoidmyconstruct(T1*p,constT2&value){new(p)T1(value);}template<classT>inlinevoidmydestroy(T*p){typedeftypenamemy_type_traits<T>::has_trivial_destructortrivial_destructor;_mydestroy(p,trivial_destructor());}template<classT>inlinevoid_mydestroy(T*p,my_true_type){cout<<" do the trivial destructor "<<endl;}template<classT>inlinevoid_mydestroy(T*p,my_false_type){cout<<" do the real destructor "<<endl;p->~T();}#endif
strings="string, to, split";istringstreamss(s);while(!ss.eof()){stringx;// here's a nice, empty stringgetline(ss,x,',');// try to read the next field into itcout<<x<<endl;// print it out, even if we already hit EOF}
std::string
可以利用std::string中的find_first_of()函数循环处理字符串
1234567891011
strings="string, to, split";stringdelimiters=" ,";size_tcurrent;size_tnext=-1;do{current=next+1;next=s.find_first_of(delimiters,current);cout<<s.substr(current,next-current)<<endl;}while(next!=string::npos);
defhandler_request(self,request):answ=self.remote_server.query(request)# this takes 5 secondsrequest.write_response(answ)
并发性低,当然可以采用多线程(多进程)处理,但是开销也较大。
但是采用异步接口,类似如下代码
123456789
defhandler_request(self,request):self.remote_server.query_async(request,self.response_received)defresponse_received(self,request,answ):# this is called 5 seconds laterrequest.write(answ)
可以参考pythond的异步网络框架twisted
源码和安装
可以利用easy_install或者pip进行安装
1
$sudo easy_install tornado
或者下载后安装
123
git clone http://github.com/facebook/tornado.git
cd tornado
sudo python setup.py install
defadd_handler(self,fd,handler,events):"""Registers the given handler to receive the given events for fd."""self._handlers[fd]=handlerself._impl.register(fd,events|self.ERROR)
defstart(self):"""Starts the I/O loop. The loop will run until one of the I/O handlers calls stop(), which will make the loop stop after the current event iteration completes. """self._running=TruewhileTrue:[...]ifnotself._running:break[...]try:event_pairs=self._impl.poll(poll_timeout)exceptException,e:ife.args==(4,"Interrupted system call"):logging.warning("Interrupted system call",exc_info=1)continueelse:raise# Pop one fd at a time from the set of pending fds and run# its handler. Since that handler may perform actions on# other file descriptors, there may be reentrant calls to# this IOLoop that update self._eventsself._events.update(event_pairs)whileself._events:fd,events=self._events.popitem()try:self._handlers[fd](fd,events)exceptKeyboardInterrupt:raiseexceptOSError,e:ife[0]==errno.EPIPE:# Happens when the client closes the connectionpasselse:logging.error("Exception in I/O handler for fd %d",fd,exc_info=True)except:logging.error("Exception in I/O handler for fd %d",fd,exc_info=True)
def__init__(self,impl=None):[...]# Create a pipe that we send bogus data to when we want to wake# the I/O loop when it is idler,w=os.pipe()self._set_nonblocking(r)self._set_nonblocking(w)self._waker_reader=os.fdopen(r,"r",0)self._waker_writer=os.fdopen(w,"w",0)self.add_handler(r,self._read_waker,self.WRITE)def_wake(self):try:self._waker_writer.write("x")exceptIOError:pass
定时器
对于IOLoop模块来说实现一个定时器非常简单,利用python的bisect模块实现如下
123456789
defadd_timeout(self,deadline,callback):"""Calls the given callback at the time deadline from the I/O loop."""timeout=_Timeout(deadline,callback)bisect.insort(self._timeouts,timeout)returntimeout
def_handle_events(self,fd,events):whileTrue:try:connection,address=self._socket.accept()exceptsocket.error,e:ife[0]in(errno.EWOULDBLOCK,errno.EAGAIN):returnraisetry:stream=iostream.IOStream(connection,io_loop=self.io_loop)HTTPConnection(stream,address,self.request_callback,self.no_keep_alive,self.xheaders)except:logging.error("Error in connection callback",exc_info=True)
#include <string.h>#include <errno.h>#include "zookeeper.h"staticzhandle_t*zh;/** * In this example this method gets the cert for your * environment -- you must provide */char*foo_get_cert_once(char*id){return0;}/** Watcher function -- empty for this example, not something you should * do in real code */voidwatcher(zhandle_t*zzh,inttype,intstate,constchar*path,void*watcherCtx){}intmain(intargc,charargv){charbuffer[512];charp[2048];char*cert=0;charappId[64];strcpy(appId,"example.foo_test");cert=foo_get_cert_once(appId);if(cert!=0){fprintf(stderr,"Certificate for appid [%s] is [%s]\n",appId,cert);strncpy(p,cert,sizeof(p)-1);free(cert);}else{fprintf(stderr,"Certificate for appid [%s] not found\n",appId);strcpy(p,"dummy");}zoo_set_debug_level(ZOO_LOG_LEVEL_DEBUG);zh=zookeeper_init("localhost:3181",watcher,10000,0,0,0);if(!zh){returnerrno;}if(zoo_add_auth(zh,"foo",p,strlen(p),0,0)!=ZOK)return2;structACLCREATE_ONLY_ACL[]=;structACL_vectorCREATE_ONLY={1,CREATE_ONLY_ACL};intrc=zoo_create(zh,"/xyz","value",5,&CREATE_ONLY,ZOO_EPHEMERAL,buffer,sizeof(buffer)-1);/** this operation will fail with a ZNOAUTH error */intbuflen=sizeof(buffer);structStatstat;rc=zoo_get(zh,"/xyz",0,buffer,&buflen,&stat);if(rc){fprintf(stderr,"Error %d for %s\n",rc,__LINE__);}zookeeper_close(zh);return0;}
/** * A simple example program to use DataMonitor to start and * stop executables based on a znode. The program watches the * specified znode and saves the data that corresponds to the * znode in the filesystem. It also starts the specified program * with the specified arguments when the znode exists and kills * the program if the znode goes away. */importjava.io.FileOutputStream;importjava.io.IOException;importjava.io.InputStream;importjava.io.OutputStream;importorg.apache.zookeeper.KeeperException;importorg.apache.zookeeper.WatchedEvent;importorg.apache.zookeeper.Watcher;importorg.apache.zookeeper.ZooKeeper;publicclassExecutorimplementsWatcher,Runnable,DataMonitor.DataMonitorListener{Stringznode;DataMonitordm;ZooKeeperzk;Stringfilename;Stringexec[];Processchild;publicExecutor(StringhostPort,Stringznode,Stringfilename,Stringexec[])throwsKeeperException,IOException{this.filename=filename;this.exec=exec;zk=newZooKeeper(hostPort,3000,this);dm=newDataMonitor(zk,znode,null,this);}/** * @param args */publicstaticvoidmain(String[]args){if(args.length<4){System.err.println("USAGE: Executor hostPort znode filename program [args ...]");System.exit(2);}StringhostPort=args[0];Stringznode=args[1];Stringfilename=args[2];Stringexec[]=newString[args.length-3];System.arraycopy(args,3,exec,0,exec.length);try{newExecutor(hostPort,znode,filename,exec).run();}catch(Exceptione){e.printStackTrace();}}/*************************************************************************** * We do process any events ourselves, we just need to forward them on. * * @see org.apache.zookeeper.Watcher#process(org.apache.zookeeper.proto.WatcherEvent) */publicvoidprocess(WatchedEventevent){dm.process(event);}publicvoidrun(){try{synchronized(this){while(!dm.dead){wait();}}}catch(InterruptedExceptione){}}publicvoidclosing(intrc){synchronized(this){notifyAll();}}staticclassStreamWriterextendsThread{OutputStreamos;InputStreamis;StreamWriter(InputStreamis,OutputStreamos){this.is=is;this.os=os;start();}publicvoidrun(){byteb[]=newbyte[80];intrc;try{while((rc=is.read(b))>0){os.write(b,0,rc);}}catch(IOExceptione){}}}publicvoidexists(byte[]data){if(data==null){if(child!=null){System.out.println("Killing process");child.destroy();try{child.waitFor();}catch(InterruptedExceptione){}}child=null;}else{if(child!=null){System.out.println("Stopping child");child.destroy();try{child.waitFor();}catch(InterruptedExceptione){e.printStackTrace();}}try{FileOutputStreamfos=newFileOutputStream(filename);fos.write(data);fos.close();}catch(IOExceptione){e.printStackTrace();}try{System.out.println("Starting child");child=Runtime.getRuntime().exec(exec);newStreamWriter(child.getInputStream(),System.out);newStreamWriter(child.getErrorStream(),System.err);}catch(IOExceptione){e.printStackTrace();}}}}
/** * A simple class that monitors the data and existence of a ZooKeeper * node. It uses asynchronous ZooKeeper APIs. */importjava.util.Arrays;importorg.apache.zookeeper.KeeperException;importorg.apache.zookeeper.WatchedEvent;importorg.apache.zookeeper.Watcher;importorg.apache.zookeeper.ZooKeeper;importorg.apache.zookeeper.AsyncCallback.StatCallback;importorg.apache.zookeeper.KeeperException.Code;importorg.apache.zookeeper.data.Stat;publicclassDataMonitorimplementsWatcher,StatCallback{ZooKeeperzk;Stringznode;WatcherchainedWatcher;booleandead;DataMonitorListenerlistener;byteprevData[];publicDataMonitor(ZooKeeperzk,Stringznode,WatcherchainedWatcher,DataMonitorListenerlistener){this.zk=zk;this.znode=znode;this.chainedWatcher=chainedWatcher;this.listener=listener;// Get things started by checking if the node exists. We are going// to be completely event drivenzk.exists(znode,true,this,null);}/** * Other classes use the DataMonitor by implementing this method */publicinterfaceDataMonitorListener{/** * The existence status of the node has changed. */voidexists(bytedata[]);/** * The ZooKeeper session is no longer valid. * * @param rc * the ZooKeeper reason code */voidclosing(intrc);}publicvoidprocess(WatchedEventevent){Stringpath=event.getPath();if(event.getType()==Event.EventType.None){// We are are being told that the state of the// connection has changedswitch(event.getState()){caseSyncConnected:// In this particular example we don't need to do anything// here - watches are automatically re-registered with // server and any watches triggered while the client was // disconnected will be delivered (in order of course)break;caseExpired:// It's all overdead=true;listener.closing(KeeperException.Code.SessionExpired);break;}}else{if(path!=null&&path.equals(znode)){// Something has changed on the node, let's find outzk.exists(znode,true,this,null);}}if(chainedWatcher!=null){chainedWatcher.process(event);}}publicvoidprocessResult(intrc,Stringpath,Objectctx,Statstat){booleanexists;switch(rc){caseCode.Ok:exists=true;break;caseCode.NoNode:exists=false;break;caseCode.SessionExpired:caseCode.NoAuth:dead=true;listener.closing(rc);return;default:// Retry errorszk.exists(znode,true,this,null);return;}byteb[]=null;if(exists){try{b=zk.getData(znode,false,null);}catch(KeeperExceptione){// We don't need to worry about recovering now. The watch// callbacks will kick off any exception handlinge.printStackTrace();}catch(InterruptedExceptione){return;}}if((b==null&&b!=prevData)||(b!=null&&!Arrays.equals(prevData,b))){listener.exists(b);prevData=b;}}}